1 Introduction¶
This document describes the decisions made in the course of implementing the Data Backbone design from DMTN-122.
2 Replication and Transport¶
The Data Backbone (DBB) will be used to move file/object data for production purposes between Data Facilities, including the US Data Facility (USDF), French Data Facility (FrDF), and UK Data Facility (UKDF). It will also be used to move “offline”, non-time-sensitive raw data from the Observatory in Chile to the USDF and potentially to the FrDF. Data products to be served directly from Data Access Centers in Chile or elsewhere (IDACs) will be moved via the DBB, as will data products sent to other partners, as described in DMTN-147.
These large-scale movements will be coordinated via Rucio,
Policies will be used to direct transfers from appropriate sources and to appropriate destinations. For example, the UKDF may obtain its data from the FrDF rather than from the USDF or the Observatory. The UKDF will not receive all raw images but instead will only receive images from a certain pre-designated portion of the sky. Appropriate metadata labels for the raw image files, as well as policies using those labels, will be configured into Rucio to enable this restrictive data transfer.
Deciding that intermediate data products are no longer needed will be handled by workflow execution or campaign management mechanisms. Rucio will be used to execute this removal across all replicas.
Download of files to end users will be provided by Virtual Observatory and/or other services within the Rubin Science Platform; it is not expected to be handled by Rucio.
Tiering of files to nearline or archival storage is handled by storage infrastructure, not Rucio.
Similarly, in a hybrid cloud model where permanent storage is on-premises but a cache is maintained in the cloud to improve latency for users, cache maintenance is the responsibility of a dedicated caching service, not Rucio.
3 Location and Metadata¶
3.1 Overview¶
The USDF will serve as the Rucio site. Rucio will maintain the global state of replication of files/objects across sites in a single central database. Rucio services will be used to transfer files to Rucio Storage Elements (RSE) at each site. Note that sites with RSEs will include the Data Facilities for Data Release Production but will also include the Chilean Data Access Center and may also include Independent Data Access Centers (IDACs) that require copies of data products. Rules set in Rucio determine how files are transferred between RSEs.
Each site has storage (file systems, object stores, tape, etc.) registered with Rucio as one or more RSEs, and each site (except possibly IDACs) will have its own local Butler registry. This registry will maintain a view of all local datasets. There are RSEs at the USDF, Chile, United Kingdom Data Facility (UKDF), and French Data Facility (FrDF). No Rucio services are running at the remote sites. All Rucio commands must call back to the USDF to perform actions.
After any action in Rucio is completed, it is logged in a Rucio database at the USDF. Rucio has a daemon, Hermes, which periodically takes new database entries, changes each one to a message, and sends the message to a message broker. Monitoring services generally use this message stream.
DBB requires that some files be automatically ingested into Butler repositories at the RSE sites after completing a Rucio transfer. We can trigger this ingestion by receiving Rucio messages, examining the message’s contents, and sending a message to a service running at the DF, which will ingest the file into a Butler repository at that site. The metadata for this ingestion includes the universal unique identifier (UUID), values for data identifier dimension components, the name of the run collection that “owns” the dataset, and, eventually, provenance information detailing how the dataset was created. This metadata will be obtained from the files themselves, if they are self-describing, such as raw image files, or else from separate JSON or YAML documents (or in the message to the broker itself), with one per file or one per batch. The exact mechanism for generating this “sidecar” metadata is TBD.
Note that Registries do not communicate directly with each other. In particular, there is no database-to-database replication associated with Butler Registries.
Also, note that there are files that are part of the permanent survey record that are not Butler datasets. These files are also transferred via Rucio according to policy, primarily to the FrDF.
3.2 Issues¶
The Hermes service reads messages from the Rucio event database, converts them to messages, and sends those messages to an ActiveMQ message broker. Once consumed by a client, these messages are no longer available. Generally, a monitoring service reads these messages for reports on the status of Rucio and, therefore, the messages can not be used by any other client. We wish to use these messages to trigger Butler ingestion once files arrive at an RSE. However, since the monitoring service already consumes these messages, we need a new method to obtain that information to perform Butler Ingestion.
Additionally, the Rucio ActiveMQ broker is local to the Rucio site, in this case, the USDF. The Butler Ingest Service (BIS) runs at each RSE site, located at the UKDF and FrDF. Therefore, we need a reliable method that allows the BIS at each location to read messages originating from the USDF without undue burden on the BIS. We don’t want the BIS to have to keep track of problems that occur due to network failure to the USDF.
Further, we wish to only transmit message traffic to the BIS specific to that RSE site. The BIS at each site shouldn’t receive messages about files upon which it can not act.
Finally, there are times when Butler ingestion requires additional information for a specific file. We wish to minimize the number of calls back to the Rucio site to obtain this information since making calls to Rucio from an RSE site is expensive.
3.3 Approach¶
The approach we will take solves all of these issues.
First, the Hermes daemon will be modified to transmit two messages instead of one. Hermes will send one message to the ActiveMQ broker, which monitoring services can use. Hermes will send the second message sent to a Kafka Message broker. The BIS will read messages sent to the Kafka Broker at each RSE site.
Second, we will install a Kafka Broker at each RSE site, replicating messages from the Kafka Broker at the USDF. The Mirror-Maker2 service handles replication. This service ensures messages are correctly copied, greatly simplifying the BIS service.
Third, we will include modifications to the Hermes service to publish messages to RSE-specific Kafka topics. We will use the contents of the database entry to see the RSE destination of landed files and write to a Kafka topic specifically for that RSE. We will configure the Mirror-Maker2 service at each RSE site only to replicate Kafka topics for that site’s RSEs. Every message transmitted to the Kafka Broker at the RSE site will be actionable by the BIS.
Finally, as we construct messages, we will perform requests to Rucio locally to obtain any additional information we require for ingestion. Then, we will add that information into the messages we create for the ingestion services at the remote site, eliminating the need to make calls from the RSE site back to the Rucio site.
3.4 Federated Message Broker Diagram¶
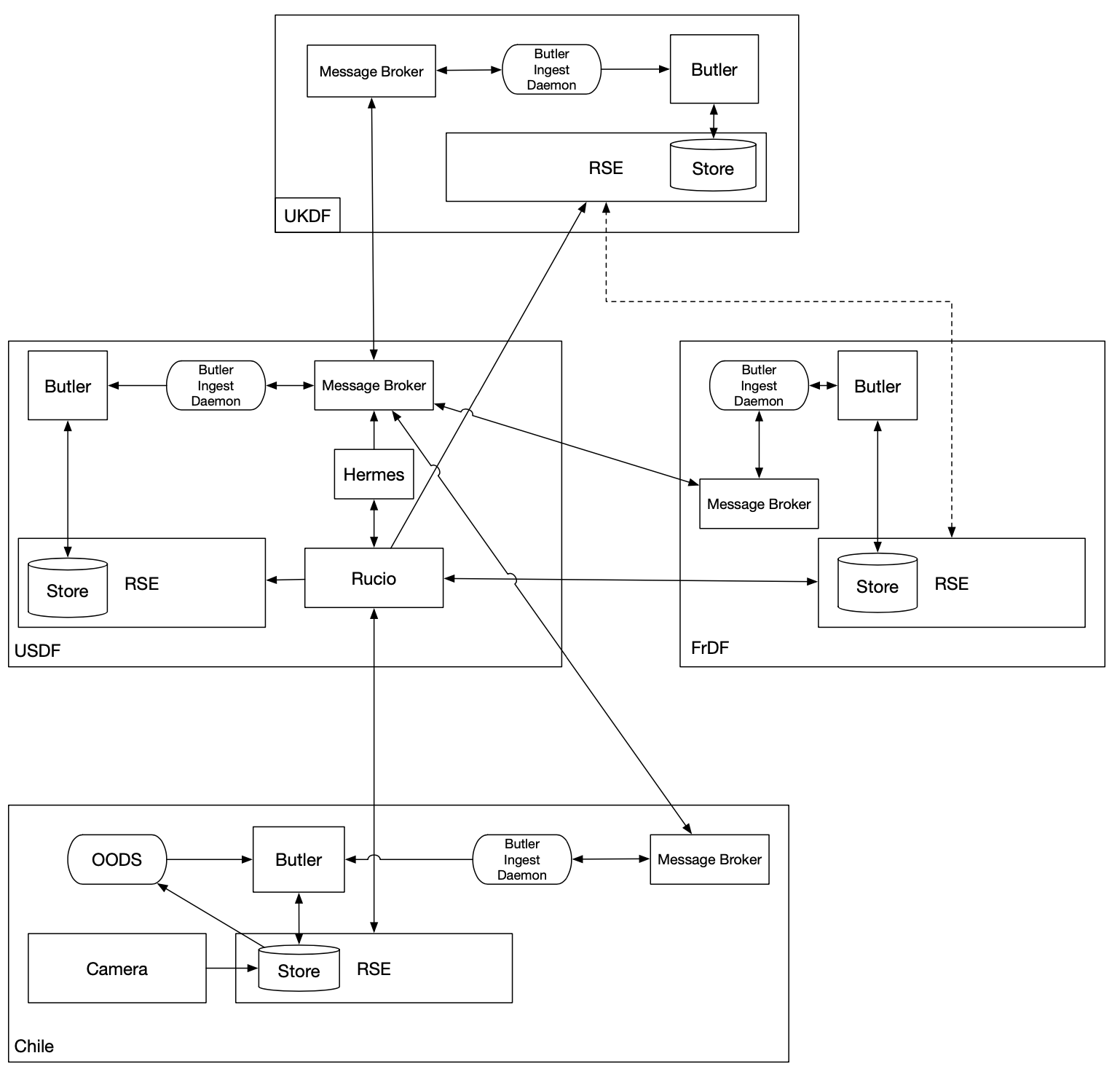
Figure 1 Federated Message Broker Diagram
This diagram shows the file transfer paths and messaging paths for DBB services. The diagram also shows the federation of message brokers, one at each satellite DF connected to the primary message broker at the USDF.
All file state changes in a local RSE are transmitted from that site using the Rucio utilities (or APIs) to communicate to Rucio at the USDF. This activity happens in all cases. For example, when a file changes state in RSE at UKDF, it must register directly to the USDF; it doesn’t proxy through the FrDF, even though the UKDF will be transferring files to the FrDF, not the USDF directly.
Each satellite site has a Butler ingest daemon that reads messages from the local broker and ingests files into the Butler at that site. The Butler ingest daemon should batch incoming messages so ingests can be grouped.
4 Files¶
Most files are expected to be stored in an object store at each location. Some locations may choose to use a filesystem instead.
The Large File Annex is currently thought of as containing two types of files: one type that is ingested into a Butler and used as a dataset and another type that remains as a read-only object only.
5 Databases¶
Qserv databases are not part of the DBB. Instead, canonical Parquet files copied via the DBB are transformed, partitioned, and ingested into local Qservs.
The Alert Production Database is internal to the Alert Production and resides only at the USDF.
The Prompt Products Database (including Solar System Objects), the Transformed Engineering and Facilities Database, the Exposure Log, and any other databases within the Consolidated Database are replicated to other Data Access Centers via native database replication technology.